Scaling electric transport optimization with Google Cloud Run Jobs

This blog post describes our journey scaling Einride’s transport optimization software using Google’s serverless high-performance computing platform, Cloud Run Jobs.
At Einride, we develop technologies to lower the carbon footprint of the transportation sector, by enabling the shift from diesel trucks to electric and autonomous trucks. We know that 1-1 replacement of diesel trucks does not cut it - electric trucks require intelligent route and charge planning to be competitive.
A core component of Einride’s freight platform is our electric vehicle route optimization engine. This engine creates optimized assignments and charging schedules for a fleet of electric trucks and chargers, ensuring that every truck can complete its route without running out of battery.
Electric vehicle routing problems (eVRPs)
An Electric Vehicle Routing Problem (eVRP) is similar to the well-known Vehicle Routing Problem, but with the added complexity of managing the limited energy capacity of electric truck batteries and the limited slots and power available at charging stations. This is a combinatorial optimization problem, belonging to the family of NP-hard problems. Finding optimal solutions is extremely challenging, especially for larger, real-world scenarios.
To give you an idea of how challenging it can be to solve an eVRP, consider this example:
In a transport network with just 10 locations, each requiring a single shipment delivery, there are 3,628,800 different possible delivery sequences. Increase the number of locations to 20, and the number of possible sequences exceeds the number of grains of sand on Earth. How can you efficiently find a cost-effective solution while simultaneously tracking charging sessions, charger availability, and charging power for each truck? This is the challenging and engaging problem we at Einride tackle every day.
Why solving eVRPs is important
Why is it important to model and solve eVRPs? At Einride, we know this is one of the essential enablers for electric transport adoption.
The big question everyone needs to answer when going electric is: “how many trucks and chargers will I need?”. An incorrect answer can lead to costly idle trucks and chargers or, conversely, too few and missed deliveries. Answering this question for any non-trivial transportation network boils down to solving and analyzing a set of eVRPs.
How to solve eVRPs
Solving eVRPs requires an eVRP optimization engine which is capable of modeling all the essential parameters of electric truck routing, including managing charging schedules and power.
Using the optimization engine to solve a single eVRP can take a long time and require lots of computational resources. In addition, identifying the number of trucks and chargers needed can require running 100s or 1000s of eVRPs, all with slightly different input parameters.
As such, to work effectively with eVRPs, you will need a high performance computing platform capable of orchestrating many demanding optimization jobs in parallel.
Solving eVRPs in Google Cloud
At Einride, we leverage Google Cloud as the underlying platform and infrastructure for most of our machine learning, AI, and optimization models. We generally prefer serverless and managed products, as they minimize infrastructure management overhead, while enabling us to build for scale.
The challenge with using serverless infrastructure is that most applications need to be designed from the ground-up to run on serverless platforms. Our eVRP optimization engine has been in development for the last 7 years, well before most serverless platforms were around - but with some initial effort, we were able to containerize it and make it possible to run serverless.
Attempt 1: Solving eVRPs using Cloud Run and Cloud Tasks
Our initial approach to running our containerized eVRP optimization engine in Google Cloud utilized the standard serverless products available at the time: Cloud Run for computation and Cloud Tasks for job management and orchestration.
We soon learned that using Cloud Run and Cloud Tasks to orchestrate long-running optimization jobs came with some challenges. Cloud Run is primarily designed for HTTP-based workloads, requiring an HTTP request (and subsequent wait) to initiate an optimization job. However, because optimization jobs can be lengthy, we wanted an asynchronous interface for our clients.
We used a Cloud Tasks queue for this purpose: the Orchestrator (see Figure 1 below) added tasks to a Cloud Tasks queue configured to call the Orchestrator again. This allowed us to solve the eVRP asynchronously without blocking the client in a synchronous call.
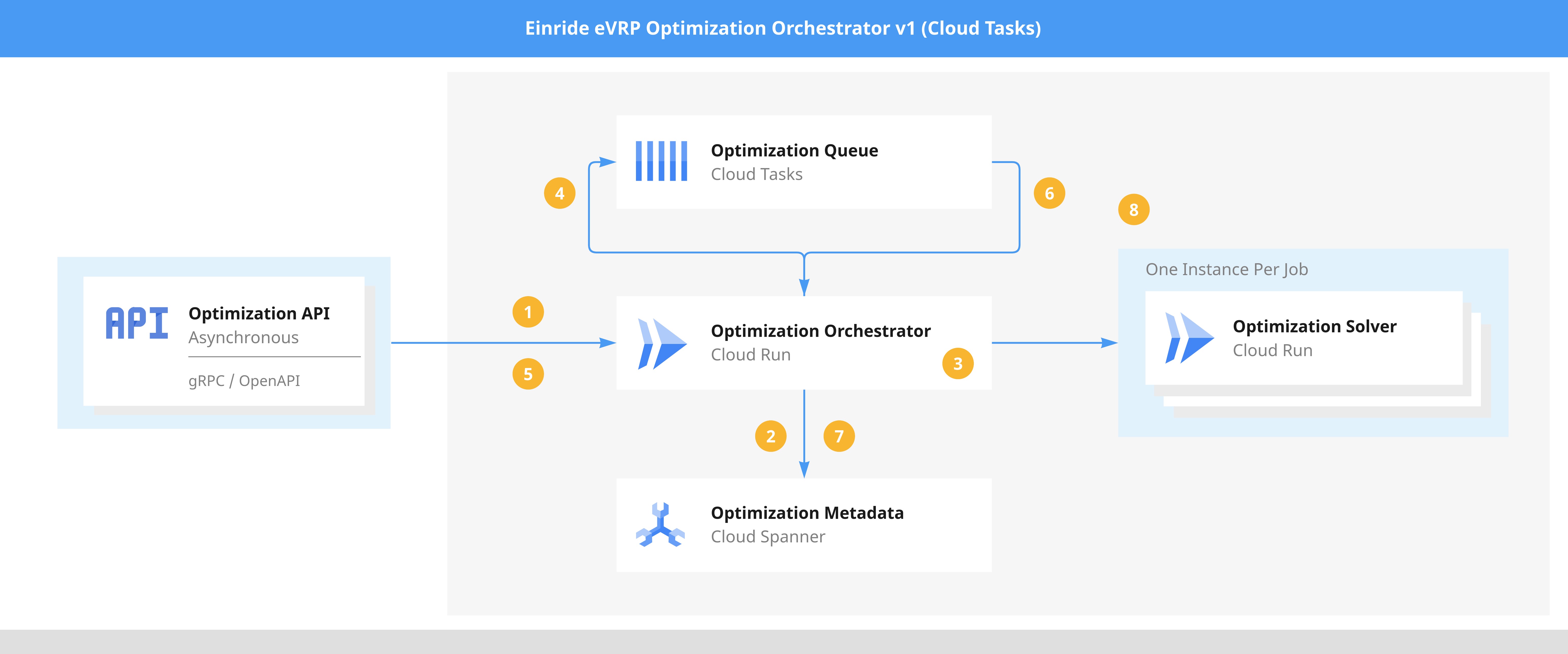
Figure 1 illustrates the components and steps involved in creating and asynchronously solving eVRPs for the client. Let's walk through the steps:
-
A client has an eVRP to be solved and posts it to the Orchestrator.
-
The Orchestrator persists the eVRP in Cloud Spanner.
-
It then analyzes the eVRP and determines whether it can be split into smaller sub-eVRPs.
-
Based on the number of splits, it creates a corresponding number of Cloud Tasks.
-
At this point, all server-side preparations are complete, and a Long Running Operation (LRO) is returned to the client. The client can use the LRO to poll the Orchestrator for progress updates.
-
Cloud Tasks invokes the Orchestrator with information about the sub-eVRP to be solved.
-
The Orchestrator retrieves the necessary information from Spanner.
-
It then invokes the Optimization Solver with the sub-eVRP and waits for it to be solved in a blocking call. When the Optimization Solver returns, the Orchestrator persists the result in Spanner. The result can either be a Solution to the sub-eVRP or an error, containing information about why it was not possible to find a solution.
The approach based on Cloud Run and Cloud Tasks worked fairly well, and we used it in production for several years. But we gradually saw a major issue with this solution - optimization jobs would occasionally fail without any apparent reason.
Because Cloud Run's interface is HTTP-based and synchronous, network errors or any disruptions to the synchronous HTTP request between Cloud Tasks and Cloud Run would halt the ongoing optimization job. The larger the optimization job, the higher the probability of such disruptions occurring during its runtime.
It wasn't until 2023 and the launch of a new serverless product that we found a solution to these problems.
Attempt 2: Solving eVRPs using Cloud Run Jobs
In 2023, Cloud Run Jobs was launched. It builds upon the existing Cloud Run platform with one key difference: instead of running container workloads in response to HTTP requests, Cloud Run Jobs starts containers asynchronously and runs them to completion.
This simplicity is compelling: within days, we had a proof-of-concept solving eVRPs using Cloud Run Jobs up and running. Instead of relying on synchronous HTTP calls, we could extend the allowed computation time for our eVRP optimization engine, enabling us to solve even larger eVRPs with longer runtimes.
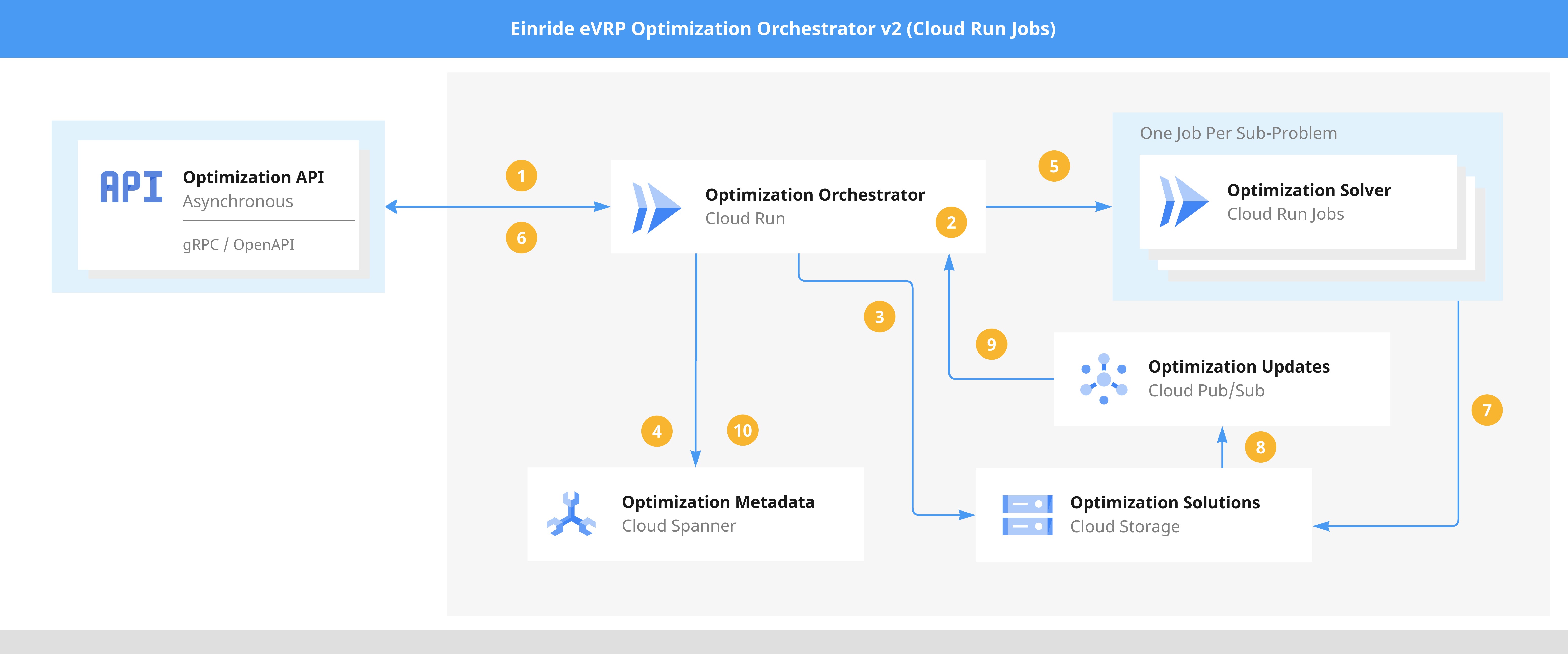
Figure 2 shows the components and steps used for creating eVRPs and then solving them using Cloud Run Jobs.
-
A client has an eVRP to be solved and posts it to the Orchestrator.
-
The Orchestrator analyzes the eVRP and determines whether to split it into smaller sub-eVRPs.
-
Each individual sub-eVRP is stored in Google Cloud Storage.
-
Metadata about the eVRP is stored in Cloud Spanner for interactive searching and browsing.
-
The Orchestrator starts a Cloud Run Job Execution for each sub-eVRP. Cloud Run Job Execution overrides inform the solver where to find the specific problem in Cloud Storage.
-
A Long Running Operation (LRO) is returned to the client.
-
The eVRP optimization engine runs to completion, writing either a solution or an error message to Cloud Storage.
-
The Cloud Storage bucket emits an event for each object created.
-
Using a PubSub push subscription, the orchestrator is notified for each file created. It specifically looks for either solutions or errors.
-
Upon receiving a solution or error object, the Orchestrator persists this information in Spanner, enabling progress tracking, which is then relayed to the client via the LRO.
After trialing this architecture as a proof-of-concept in parallel with our previous architecture, we soon noticed that it was superior in every way.
Free from the constraints of HTTP requests, we were able to extend the container timeout for up to 24 hours. With a high-performing eVRP optimization engine, this is plenty of time to solve most reasonably sized problems.
Furthermore, because our engine uses metaheuristics to continuously search for better solutions, eliminating the HTTP-induced flakiness allowed jobs to run slightly longer, leading to a roughly 4% reduction in total driven distance due to more efficient fleet-level delivery and charging schedules.

This reduction in driven distance allowed us to transport more shipments with the same number of vehicles, freeing up capacity for new business.
In some cases we kept the computation times short, for rapid prototyping of delivery schedules, and to manage cloud costs. Cloud Run Jobs provided the flexibility to tailor computation times to specific business needs. Overall, migrating to Cloud Run Jobs resulted in a 20% reduction in our eVRP optimization engine's cloud costs.
Learnings
This blog post demonstrated how we leveraged Cloud Run Jobs, a serverless high-performance computing platform, to scale and improve the performance of our eVRP optimization engine while simplifying architecture and reducing cloud costs.
Adopting a serverless approach and fully utilizing managed cloud services requires containerization and sometimes re-architecting your application. Combining serverless products like Cloud Run Jobs, Cloud Run, Cloud Pub/Sub, and Cloud Spanner into an effective solution might not always be straightforward. For us, some trial and error was necessary, but getting together with some colleagues in front of a whiteboard, iterating on the architecture until we got it right, was time well spent.