A Safety-first Approach to Explainable E2E Autonomous Driving

This blog post presents how Einride Autonomous is developing an explainable end-to-end driving stack for its autonomous trucks and how it is designed to leverage redundant layers for improved safety.

A Safety-first Approach to Explainable E2E Autonomous Driving
The autonomous vehicles journey keeps convincingly pointing towards architectures capable of
operating in diverse environments – e.g. urban, highway, or off-road scenarios – and handling wide
arrays of probable driving events as well as unlikely and potentially hazardous situations. While
these broad generalization capabilities represent an impressive goal, for autonomous solutions
deployed on public roads – and heavy-duty trucks in particular – safety is the ultimate benchmark.
The picture below shows the end-to-end autonomous driving stack we are developing at Einride, with
built-in redundancy and no reliance on safety drivers to make sure we can safely handle the
complexity our trucks' operational environments.
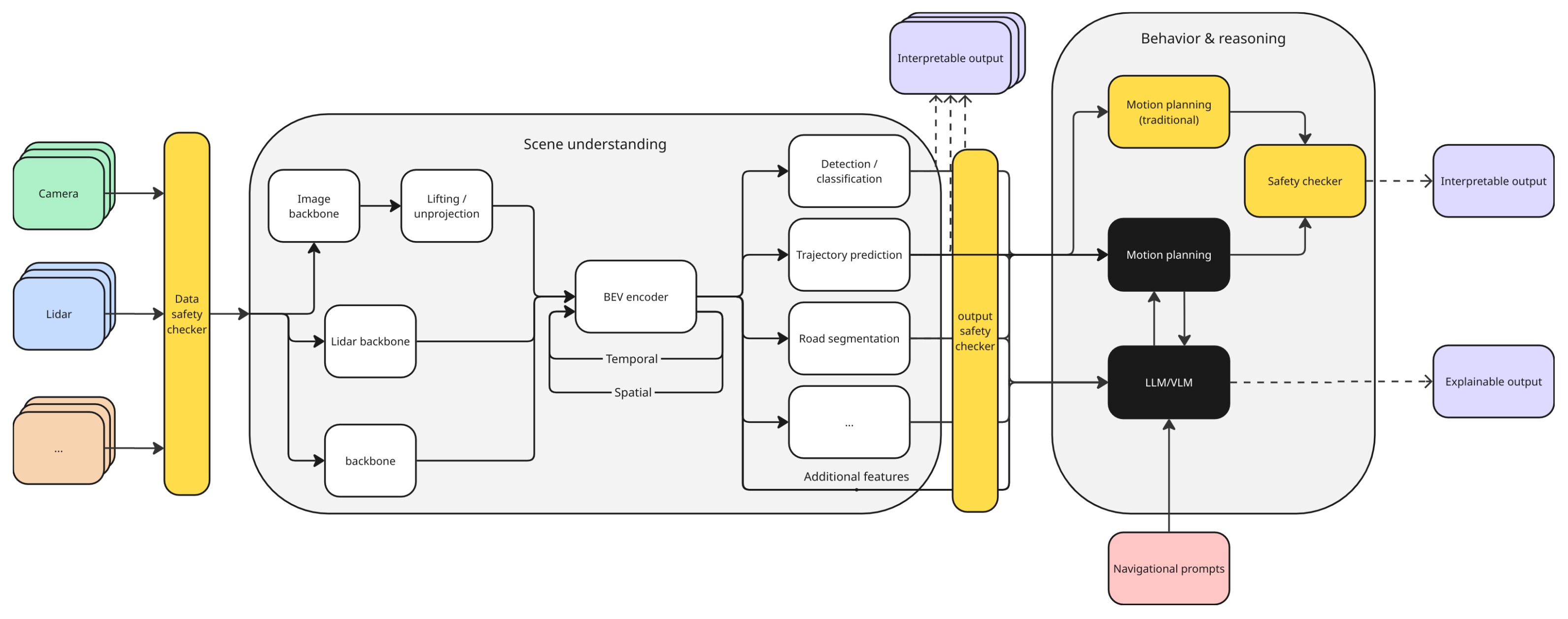
By incorporating safety into the core architecture, we ensure it's an integral part of the system taking precedence over the addition of new features, which results in trucks that are deployable, safe, and compliant with all relevant automotive standards. Explainable Machine Learning (XAI) is the critical pathway to reconcile safety and technological advancement, by providing the transparency needed to ensure that our autonomous trucks behave in ways that are robust, understandable, and demonstrably safe.
Explainable E2E Autonomous Driving Stack
Modern machine learning approaches have revolutionized how autonomous driving systems are designed,
moving away from traditional modular stacks – with cascading subsystems that are optimized
independently – and towards a joint optimization problem. Traditional driving stacks address
perception, prediction, and planning in a sequential fashion, and often require hand-engineering and
extensive rulesets for adequate performance. On the other hand, end-to-end architectures aim to
directly map raw sensor inputs to driving actions or actuation commands, jointly optimizing the
whole decision-making process and implicitly learning the intermediate tasks. By ingesting
multi-modal sensor data — fusing information from cameras, LiDAR, and radar — these models build a
representation of the environment that is used to simultaneously derive an understanding of static
and dynamic elements (perception), forecast the behavior of other agents (prediction), and generate
ego-vehicle trajectories (planning).
This paradigm shift marks a significant evolution: due to their sequential nature, early stages in
traditional architectures (e.g. perception) can discard contextual cues that are relevant for
subsequent subsystems (e.g. planning), jeopardizing the optimality of the final solution. In
contrast – by addressing all tasks at once – end-to-end approaches optimize using the full available
information, yielding more robust solutions, with broader generalization capabilities and improved
contextualization.
How to Explain and Interpret a Black Box
The main challenge of end-to-end architectures is their "black-box" nature, which inevitably raises
critical questions about safety, especially when deploying, and debuggability during the development
phase.
This is where the principles of Explainable AI (XAI) and Interpretability come into play.
Explainability is the ability to provide a human-understandable justification for why a model
made a specific decision or prediction, clarifying the reasoning behind an output.
Interpretability, on the other hand, is about understanding how the model works, offering
insights into its internal mechanisms, for example how sensor inputs are mapped onto driving
actions.
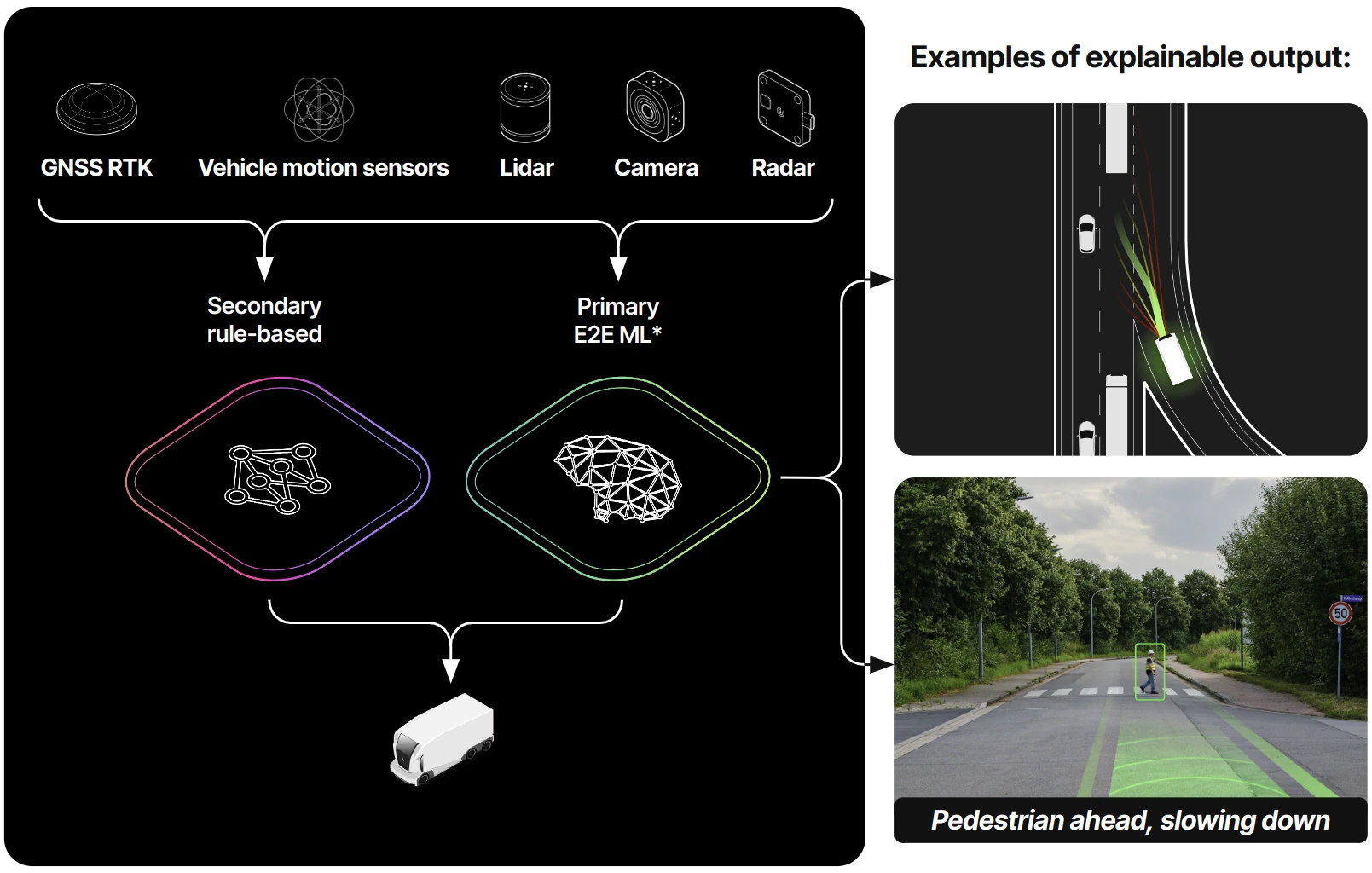
The image above provides a quick view into what type of technique we are developing to improve the
explainability and interpretability of our end-to-end system.
Interpretable outputs, such as bounding boxes around pedestrians and traffic signs or segmented
lanes help us understand how well the (latent) perception block is performing. Similarly, feasible
ego-vehicle trajectories and driving plans provide clarity on (latent) prediction and planning.
To increase the explainability of the system, we are instead exploring the extent to which post-hoc
explanations in the form of textual feedback, for example "pedestrian ahead, slowing down", can be
successfully used to justify the rationale behind decisions made in increasingly complex driving
scenarios.
Redundancy
Redundancy is instrumental in building a safe and robust autonomous driving stack, ensuring there
are no single points of failure that could compromise safety or lead to an accident. This is
especially true in the complex scenarios our trucks are expected to navigate where they will be
exposed to many weather conditions, vibrations, dirt and more. Redundancy is just as important when
designing the software and machine learning components.
Both (latent) perception and planning blocks of our end-to-end stack have redundant layers in place
to ensure robustness throughout the entire system, and the interpretable outputs our end-to-end
system generates are validated against these redundancies. As the (latent) perception block
addresses multiple tasks at once, its redundant counterpart is built on the layering of two
different subsystems, one to enable proactive behaviors, such as adaptive cruise control, and
another to implement emergency maneuvers – a low-level, low-latency component that serves as a
safety mechanism in case of emergency scenarios involving other actors on the road or system
degradations, such as failing sensors.
The redundancy for the (latent) planning block is built on layering an ML-based planner and a
state-of-the-art algorithmic planner. These produce multiple feasible paths that are compared
against one another, and the best one is run through trajectory validation before the actuation
step.
Challenges
Designing a safe, explainable end-to-end autonomous driving stack is an extremely complex undertaking. The standards we hold ourselves to require our autonomous trucks to be capable of safely handling a wide variety of driving conditions, from probable scenarios to unlikely and potentially hazardous ones. Through simulation and fleet-scale data collection long tail distribution of events. However, diagnosing potential model issues and determining the reason for undesired behavior is not trivial.
The power of end-to-end approaches, namely their ability to learn highly non-linear mappings from raw sensor data directly to actions, also reduces their inherent explainability. While there are many ways to extend end-to-end models for greater explainability, each comes with its own pros and cons. For example, some methods only provide post-hoc explanations which, while useful for diagnosing why certain actions were taken, don't directly prevent undesired behavior. Other methods might offer more direct feedback, but proving the alignment between these explanations and the model's actual reasoning can be challenging. By adopting multiple methods and continually evaluating new methods to increase explainability, we leverage the strengths of each and gain a more complete understanding.
Another challenge is how to decide the correct, and safest, course of action if a failure of the end-to-end model is detected. Our built-in redundancy plays a major role here, allowing our trucks to act safely in case of system degradations or failures.
Looking ahead
Safety and explainability are core design principles of our next-generation driving stack. Our vision is ambitious — a high-performance autonomous truck operating safely across diverse operational environments, from industrial to urban — and our explainable end-to-end autonomous driving stack is the key enabler of this future.